
Abstract
Acknowledging that traditional matrix-form customer portfolio models that result in crisp clusters are clouded with ambiguity, we propose the use of fuzzy clustering in customer portfolio analysis. This has been done in order to assist managers in better understanding their overall customer portfolio and reducing the effect of descriptive indicators. Our approach is tested on a supermarket data set of 3076 customers and its results are compared with a conventional customer portfolio matrix. A qualitative and quantitative assessment of the categorization generated both by our fuzzy clustering approach and the conventional matrix-based crisp clustering has been carried out along the following parameters: substantiality and balance of portfolio. The results show that the use of fuzzy clustering yields more substantial clusters, as well as a more balanced portfolio of customers. Although a particular portfolio matrix has been chosen for this research, the approach proposed here could be modified for use with other portfolio matrices.
Similar content being viewed by others


INTRODUCTION
Managing customer portfolios has been a critical issue for many organizations. Researchers have proposed many different portfolio matrices to allow better categorization of customers in order to enable organizations to make more informed resource allocation decisions. However, many of the existing models are found to be limited in handling uncertain, ambiguous and incomplete data. The fuzzy set theory is one approach to reduce this ambiguity, which requires the modelling of the descriptors using fuzzy terms.
The purpose of this article is to show that fuzzy clustering yields a more refined classification and maybe more useful to organizations than the matrix-form portfolio models-driven crisp clustering approach. To achieve this, a methodology rooted in the data-mining framework is followed where the data set is used to form crisp clusters based on the traditional matrix-form models and fuzzy clusters based on the fuzzy clustering approach. The critical issue involves finding evaluation criteria between clusters produced by the traditional matrix-form models and the proposed fuzzy clustering approach in order to draw conclusions on which method yields better results.
The study commences with a review of the existing literature. It then describes the methodology employed for our empirical study and presents the results. The results are analysed using substantiality and balance of portfolio as the main criteria. The analysis of data is not limited to a quantitative assessment. The implications for marketers or managers are also discussed. It is concluded that the fuzzy clustering approach proves to be more useful to practitioners in reaching a more accurate representation of their customer portfolio.
LITERATURE REVIEW
In line with the ascent of relational approaches in marketing, studies dealing with customer portfolios have been conducted for a couple of decades.1 Kundisch et al 2 provide a comprehensive definition of customer relationship management (CRM). According to Kundisch et al,2 CRM centres on the valuation, selection, acquisition, retention and development of durable customer relationships with the objective of allocating limited resources in order to maximize the value of a company.3 Ittner and Larcker4 suggest that proactive management of customer relationships can increase profitability of the firm as a whole. This makes CRM very important both from a business and academic perspective and this is reflected in the plentiful research carried out on this topic.
One of the concrete tools of CRM is customer portfolio analysis. The generic term ‘Portfolio Analysis’ refers to the process of reviewing a group of investments usually with a view to make asset management or resource allocation decisions.5 In the consumer portfolio context, these investments or assets are the consumers of the focal company. Terho and Halinen6 define consumer portfolio analysis as an activity by which a company analyses the current and future value of its customers for developing a balanced customer structure through effective resource allocation to different customers or customer segments.7
Many studies dealing with customer portfolios have been conducted since the 1980s. Table 1 provides a summary of these studies. In line with contingency theory, some authors propose the need for different kinds of relationship marketing and management depending on the exchange context of the interacting firms.6 Thus, the context within which the particular model maybe relevant is also stated along with the variables that the model deals with. Empirical research conducted by different researchers to test the various models can also be found in the table. It should be noted that the traditional portfolio models allow a data point to be present only in one class at a time, and hence the name crisp classification. For example, in the well-known Boston Consulting Group Matrix, a particular business (data point) can either be a star or a cash cow or a question mark or a problem child. This table is adapted from Talwar et al. 8
On the basis of the studies mentioned in Table 1, it can be noted that subjectivity and ambiguity of the different axes is a common problem while trying to operationalize most of the models. Gelderman17 finds the definition of the dimensions and constructs to be ambiguous in the portfolio models. Yorke and Droussiotis11 go a step further to say that the customer portfolio models are limited to aiding visualization.
We propose the use of fuzzy clustering as a customer portfolio analysis tool that minimizes the ambiguity of the results. Fuzzy clustering is based on the fuzzy set theory that allows us to describe and treat imprecise and uncertain elements present in a decision-making problem.18, 19 It may provide an alternative and convenient framework for handling uncertain project parameters (for example: project value, cost and so on) while there is lack of certainty in data or even lack of available historical data.20
The most important and common fuzzy clustering algorithm is fuzzy c-means, which was first proposed by Dunn21and then developed by Bezdek.22 It is based on an objective function and was the birth of all fuzzy clustering methods and was developed from the traditional k-means method.23 These fuzzy c-means algorithms have been applied and studied in different areas and more details of the development of these methods can be found in Yang.24 For the mathematical details, please refer to Bezdek22 and Dunn.21
The use of the fuzzy set theory is most prevalent in stock portfolio selection tools where it is used to reflect the vagueness and ambiguity of security returns when probability theory proves inadequate. This is evident in the multitude of research on the application of the fuzzy set theory in a financial stock portfolio context.25, 26 Apart from stock portfolio selection, the fuzzy set theory has been employed to represent uncertain or flexible information in many types of applications such as scheduling, engineering design and production management.20 Wang and Hwang20 apply fuzzy logic to the process of R&D portfolio selection. Lin et al 27 talk about the application of the fuzzy set theory to evaluate different projects, for example, R&D,28 IT29 and Operations Management.30 Some applications of fuzzy logic are also seen in the marketing area, specifically in product innovativeness31 and new product development and project selection.32
The use of the fuzzy set theory in a purely customer relationship context has received very limited academic attention. Zumstein33 does focus on the application of fuzzy classification in CRM, but its specific application to customer portfolio analysis is not studied. Lin et al 27 propose a systematic approach that incorporates the fuzzy set theory in conjunction with portfolio matrices to assist managers in reaching a better understanding of the overall competitiveness of their business portfolios. Even though customer relationships are a part of the study, fuzzy logic is not applied directly to the customer relations context. Starting from the suggestion that customers are the firm's most important ‘assets’34 and linking it to the applicability of the fuzzy set theory to the selection of a portfolio of financial assets or stock, it is reasonable to suggest that the fuzzy set theory can find application in Customer Portfolio Analysis. This study is unique as it demonstrates a direct use of fuzzy clustering in customer portfolio analysis. Second, it draws a comparison between traditional matrix-form clustering and fuzzy clustering from a marketing point of view and, in doing so, it uses specific comparison criteria of substantiality and balance of portfolio. No study can be found that mentions bases of comparison common to both fuzzy and crisp clustering. Third, it discusses the managerial implications that the more substantial clusters and more balanced portfolio of customers can have for an organization.
METHODOLOGY
Proposed research model
The study makes use of transactional data of 3076 supermarket customers of a UK-based supermarket chain over a period of 4 months. A clustering task is undertaken on these customers using two different approaches – crisp clustering or traditional matrix-form clustering and fuzzy clustering. Certain comparison criteria are set such as substantiality and balance of portfolio that enable a comprehensive comparison between the two sets of produced clusters in order to provide an indication about which clustering approach is more useful to marketers.
The study involves the use of the data-mining methodology. CRM necessitates management and analysis of large volumes of market and consumer data using complex data management infrastructure and technology. Data mining acts as a helpful tool for organizations to discover meaningful trends, patterns and correlation in their customer data. These then enable them to drive improved customer relationships and to decrease the risk of business operations.35
The variables used are shown in Table 2.
The details on the operationalization of each variable can be found in Appendix A.
Research questions and hypotheses
Before the clustering results can be compared, two main issues need to be addressed. First, it must be ensured that the data being used are not normally distributed, as this is a prerequisite for clustering. The specific research question that addresses this concern is:
-
1. Are the data that are obtained normally distributed?
Given that the data do not follow a normal distribution, the second concern is regarding the identifiability and distinguishability of the clusters from each other. It is necessary to check whether the clusters are identifiable and distinguishable in terms of the variables ‘Value’, ‘Cost’ and ‘ATUQ’. In other words, one needs to ascertain whether the average values of the variables are found to be different across the clusters. It must be noted that this is not a comparison between a fuzzy cluster and a crisp cluster but rather among the different crisp and fuzzy clusters. The research question addressing this issue is:
-
2. Can the clustering approach (crisp and fuzzy) produce clusters that are identifiable and distinguishable in terms of the variables?
Having addressed these issues, the study must deal with the primary issue of comparing the crisp clustering approach to the fuzzy clustering approach in order to see which one of the two is a more refined clustering technique from a marketer's point of view. This study draws comparison between the two approaches by using substantiality and balance of the portfolio as the criteria. The specific research questions concerning these are:
If the clusters exist, are the fuzzy clusters more useful to marketers than the crisp clusters?
-
1
Does fuzzy clustering produce more substantial clusters than traditional clustering?
-
2
Does fuzzy clustering lead to the formation of a more balanced portfolio than traditional clustering?
The hypotheses corresponding to the above-mentioned research questions are:
Hypothesis 10:
-
The data points show a bell-shaped distribution.
Hypothesis 20:
-
The crisp clusters are not identifiable and distinguishable in terms of the variables.
The fuzzy clusters are not identifiable and distinguishable in terms of the variables.
Hypothesis 30:
-
Fuzzy clustering does not produce clusters that are more substantial in terms of size and value under the two approaches.
Hypothesis 40:
-
Crisp clustering produces more balanced portfolio than fuzzy clustering.
Research procedure
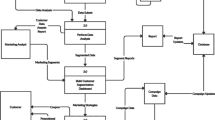
The methodology follows six steps as illustrated in Figure 1:

Study methodology.
Data Collection: The research sample used in this study is in the context of the retail industry. The data were procured from an online database and are collected from a supermarket chain in the United Kingdom.
Data Preparation: Three behavioural characteristics of customers – Recency (R), Frequency (F) and Monetary (M) value – were extracted along with the total number of unique products they buy. The necessary data were extracted using MySQL from the database.
Data Pre-processing: Data pre-processing refers to the process of getting rid of noisy data or missing values by filtering or deleting them and doing some transformation or normalization that is crucial before mining the data.
The pre-processing steps employed for the data with their explanations are shown in Figure 2.

Data pre-processing stages.
For a more detailed explanation on the pre-processing process, refer to Appendix B.
For this study, a simple random sampling method was used to extract the sample instead of using the whole database. Approximately, 10 per cent of the database was used as the study sample. By means of a sampling code written using Microsoft SQL, a sample of 3076 customers was obtained for conducting the analyses. Three reasons justify this approach. First, the use of the entire database could have resulted in criticism of the study on the grounds of statistical validity. Second, it is believed that a solution achieved from using a certain sampling method can be as effective as using the whole database.36 Third, using the entire database could have necessitated the use of high-powered computers, which were not available for this study.
Data Analysis – Matrix-form portfolio models: The crisp clustering exercise has been carried out using the RFM tool in the SPSS software. However, a slight modification has been made wherein instead of entering the RFM values as the variables, ‘value’, ‘cost’ and ‘ATUQ’ were entered.
Data Analysis – Fuzzy clustering: Fuzzy c-means is the clustering method that is used. In order to perform the analysis, NCSS Data software is used. The parameters used are given in Appendix C.
Comparison of Results using Substantiality and Balance of Portfolio: The criteria chosen for comparing the two sets of clustering results are substantiality and balance of portfolio. Below is a brief description of the methods used to assess substantiality and balance of portfolio.
Substantiality can be measured in terms of number of customers belonging to each cluster, as well as the total value that each cluster accounts for. Value is usually measured in terms of a profit or a revenue function. However, in this study, the total value that each cluster contributes is measured in terms of the variable ‘Value’, which is a sum of the RFM values. The reason behind this is that monetary value is not the only factor that supermarkets want to drive; they also want their customers to be frequent and regular customers. For the crisp clusters, it is easy to find the number of customers belonging to each cluster and the corresponding value that they contribute. However, to count the number of customers belonging to each fuzzy cluster, one must set a benchmark membership degree or alpha-cut. If the membership degree exhibited by a customer exceeds this alpha-cut, then he/she must be accounted for in that cluster. Thus, the number of customers in each cluster and the value contributed by each cluster is obtained for both crisp and fuzzy clustering approaches and a comparison is drawn to decide which technique results in more substantial clusters.
This test is based on a study by Hiziroglu.37 However, it has been modified to suit the clustering context from the segmentation context where it has been earlier applied.
The objective is to determine which of the two clustering approaches – fuzzy and crisp clustering techniques – produce better-balanced portfolio of customers. Zumstein33 uses the following formula to calculate the balance error in a portfolio:

where Norm (O i |C 1) is the normalized membership degrees of customer i with respect to cluster 1, OW c1 is the optimal weight allocated to cluster 1, and BE is the balance error.
Even though this formula is specific to fuzzy portfolios owing to the presence of membership degrees as a variable, it has been used in our study to calculate the balance error for fuzzy and crisp clusters. For crisp clusters, the membership degree of a customer belonging to crisp cluster 1 is counted as 1 and those belonging to other clusters are represented as 0 while computing the first term of the equation. For the second term, membership degrees of customers belonging to crisp cluster 2 are counted as 1 and the others are represented by 0 and so on for the remaining terms. Our study uses a modified version of the equation used by Zumstein.33 The above-mentioned formula is converted into an objective function that aims to minimize the balance error for the crisp clusters and calculates the optimal weights for each of the crisp clusters. Similarly, an objective function that minimizes the balance error for the fuzzy clusters is devised and the corresponding optimal weights for the fuzzy clusters are found. The constraints for these objective functions are that the optimal weights should be between 0 and 1 and the sum of the optimal weights should not exceed 1. Using the Microsoft Excel Solver, the minimized balance error and corresponding weights for both the crisp and fuzzy approach are found. Zumstein33 states that an optimally well-balanced portfolio has a balance error equal to 0. The minimized balance error for the crisp portfolio and that for the fuzzy portfolio is compared to decide which approach yields a balance error closer to 0, and thereby allows the creation of a well-balanced portfolio.
RESULTS OF THE ANALYSES
This section presents the results of the analyses conducted on the data. A brief insight into the descriptive statistics is provided followed by the presentation and interpretation of the clustering results. The results are compared using substantiality and balance of portfolio as evaluation criteria and the managerial implications for more substantial clusters and a well-balanced portfolio are discussed.
Descriptive statistics
The descriptive statistics provide a better understanding of the empirical data that are used in the study. Some of the descriptive statistics are shown in Table 3.
It can be seen that the mean values for the variables ‘Value’, ‘Cost’ and ‘ATUQ’ are 0.28023, 0.00246 and 0.14271, respectively.
A prerequisite for the clustering is that the data used must not be normally distributed. Hence, it is imperative to verify that the data employed in this study do not follow a normal distribution. The hypothesis for the first research question is:
Hypothesis 10:
-
The data points show a bell-shaped distribution.
There are a few ways to verify this. A simple way is to look at histograms for each variable as these allow us to observe the distribution of the variables visually. The histograms for the variables are presented in Figure 3.

Histograms of each variable.
It is visible from the histograms that the distributions for all three variables are rightly skewed, and hence not normal.
Another way of inferring whether the data are normally distributed or not is by performing a Kolmogorov–Smirnov test. The results of the Kolmogorov–Smirnov test are presented in Table 4.
The Z-values are found to be 2.842 (P<0.05), 7.720 (P<0.05) and 8.562 (P<0.05), respectively, which indicate that the distribution is not normal. The null hypothesis is thus rejected.
Presentation of the final clusters
Table 5 presents the means of the variables and the number of customers assigned to each cluster as per the crisp clustering method.
It can be seen that the clusters are evenly distributed with almost the same number of assignments to each cluster. Three-dimensional representation of the crisp clustering results is given in Figure 4.

Three-dimensional representation of the crisp clustering results.
Table 6 shows the means of the variables and the number of customers assigned to each cluster as per the fuzzy clustering method. It must be noted that the number of customers here is a sum of the membership degrees of all customers towards the particular cluster. Thus, the real number of customers in the fuzzy clusters is calculated according to the total belongingness to each cluster.
It can be observed that once again clusters 5 and 6 are the two most heavily populated clusters, followed by cluster 8. A three-dimensional representation of the fuzzy clustering results is shown in Figure 5.

Three-dimensional representation of the fuzzy clustering results.
Testing the results on identifiability and distinguishability
So far, we have checked whether the prerequisite for clustering is met and then the results under the two approaches have been presented. Now, it is essential to determine whether the clusters are identifiable and distinguishable from each other in terms of the variables used, and thereby answer the second research question. The null hypothesis pertaining to this issue is:
Hypothesis 20:
-
The crisp clusters are not identifiable and distinguishable in terms of the variables.
Robust tests of equality of means were conducted for the crisp and the fuzzy clusters. This test helps to check whether the mean values of the variables are different for each of clusters 1–8 within crisp and fuzzy clustering. The results of this test are shown in Table 7.
It can be seen that the significance levels for the three variables under both the measures and for both crisp and fuzzy clusters are less than 0.05. Thus, it can be concluded that the clusters are identifiable and distinguishable in terms of the variables, and the null hypothesis H20 is thus rejected. In simpler terms, cluster 1 varies from cluster 2, varies from cluster 3 and so on in terms of the variables used for both the crisp and fuzzy clusters.
Interpretation of the results
Before going on to the comparison of the clustering results, it would be helpful to give an interpretation of the results of the membership for a very small representative sample. The extracted sample contains 10 customers along with their belongingness or membership degrees exhibited towards each cluster and their crisp cluster assignment. It is shown in Table 8.
The fuzzy clustering approach produces membership degree values (shown in table as MD) that show the belongingness of each customer to the different clusters. It is an indicator of the extent to which customers share the characteristics of a given segment. Table 8 suggests that the customers exhibit various types of memberships in terms of their belongingness to the different clusters. Some are explicitly closer to one single segment than they are to other segments as seen in row 2. The customer shows belongingness to cluster 1 to the extent of 0.784 and their membership degree to the other clusters is almost negligible. Few customers may also show an equal belongingness to two or more segments as seen in row 1 of Table 8. The customer shows almost equal belongingness to clusters 1 and 2 of 0.367 and 0.351, respectively. It is not unusual to find customers who may possess characteristics of all the clusters with close membership degrees as seen in row 3. Various such patterns of belongingness can be discovered in the given data set.
Given that customers can belong to multiple clusters, a thumb rule is needed in terms of the membership degree in order to decide which clusters a particular customer belongs to. Setting an alpha-cut value that acts as a benchmark level does this, and customers with membership degrees higher than the alpha-cut value are considered a part of the cluster. For example, if the alpha-cut value is 0.3, then a customer with membership degree higher than 0.3 with respect to clusters 3, 4 and 6 will be said to belong to all the three clusters. Of course, the determination of the alpha-cut value is subjective but this gives the organizations the freedom to set their own alpha-cut values depending on the specific conditions. There exist two generic approaches to setting the alpha-cut values. One rule is to set the alpha-cut value equal to the smallest value of the average membership degrees of each segment, which, in this case, is 0.064. The second approach is to set alpha-cut at a value greater than or equal to 1/c, where c is the number of clusters. As per this rule, the relevant alpha-cut value in our case should be greater than or equal to 0.125. Therefore, different alpha-cuts of 0.15, 0.2 and 0.3 are used to represent different scenarios.
Comparison of results
Hypothesis test for substantiality
This study views substantiality as a combination of both cluster size and cluster value. Cluster size is the total number of customers belonging to each cluster. Therefore, the hypothesis to be examined is as follows:
Hypothesis 30:
-
Fuzzy clustering does not produce clusters that are more substantial in terms of size and value under the two approaches.
To test the above hypothesis, cluster size and cluster value were calculated for both approaches. A comparison of cluster size between the two sets of clusters is given in Table 9. In order to interpret this table, one needs to distinguish between the real number of customers and integer number of customers. While computing the real numbers, only total belongingness is considered, which is the sum of the membership degrees of all customers of a particular cluster. Integer numbers are calculated by setting an alpha-cut value, and every customer having membership degree towards a particular cluster greater than the preset alpha-cut is counted as part of the cluster. The table shows the number of customers in fuzzy clusters for different alpha-cuts of 0.15, 0.2 and 0.3. These alpha-cuts are chosen such that they are close to the 0.125 benchmark alpha-cut value as calculated above.
One may observe that for the alpha-cut=0.15, all the fuzzy clusters are greater in size than the crisp clusters. For alpha-cut=0.2, cluster 4 turns out to be smaller in size than the corresponding crisp cluster. For alpha-cut=0.3, clusters 1, 3, 4 and 7, the fuzzy clusters, are smaller in size compared to the crisp clusters. Thus, it might be optimal to use the average cluster size as the base of comparison. On an average, fuzzy clustering does produce more substantial clusters than crisp clustering. Thus, the first part of the null hypothesis H30 can be rejected.
The real and integer numbers represent the lower and upper limits of the cluster, respectively. It is reasonable to say that less the difference between the lower and upper limit of the cluster, the more stable is the cluster. Cluster 4 seems to be most stable of all the clusters.
It is also essential to look at the value that the different clusters contribute while drawing conclusions about cluster substantiality. This is presented in Table 10.
Again, using the average cluster value as the base for comparison, it is seen that fuzzy clustering allows the formation of clusters that contribute more value than crisp clusters for our alpha-cut values. Setting a very big alpha-cut value such as 0.7 will lead to a drop in cluster size and, consequentially, lead to a drop in cluster value below than that of the crisp clusters. However, setting such a high alpha-cut value is not practical.
Implications for marketers
Fuzzy clustering allows the creation of more substantial clusters. Thus, marketers can have a larger customer base in each cluster to target and greater economies of scale may also be achieved.
Varying the alpha-cut value allows implementation of the fuzzy clustering approach to different situations. For example, while sending emails to existing customers about a new product launch, the organization can set a low alpha-cut, say 0.15, as the purpose is to spread information and can be done rather cost effectively. However, if the organization is holding a special event to launch a premium product, the organization can set a high alpha-cut, whereby only customers who show a very high belongingness to a particular cluster are sent the invite.
Fuzzy clustering provides the upper and lower limits for the cluster and thereby allows us to draw conclusions on the stability of the cluster. Crisp Clustering does not enable this and, hence, no comment on the stability of the cluster can be made while using the traditional clustering tools.
Setting a high alpha-cut value may result in fuzzy clusters being less substantial than crisp clusters. However, the aim here is not limited to showing that the average cluster size or value for fuzzy clusters is higher than crisp clusters. What also needs to be highlighted is that fuzzy clustering makes the marketing managers much better aware of the size and corresponding value of the clusters with the different alpha-cut values.
Hypothesis test for balance of portfolio
An optimally well-balanced portfolio exhibits a balance error equal to 0. The hypothesis under examination is:
Hypothesis 40:
-
Crisp clustering produces more balanced portfolio than fuzzy clustering.
In terms of balance error, this hypothesis implies that the balance error under crisp clustering is closer to 0 than that for fuzzy clustering. To test the above hypothesis, the balance error for both the crisp and fuzzy portfolios is minimized and the corresponding optimal weights are found. The results of the test are given in Table 11.
Minimizing the objective functions for crisp clustering and fuzzy clustering yields a balance error of 1318 and 0.004, respectively. It is easily seen that the balance error for the fuzzy portfolio is much closer to 0 than for the crisp portfolio. Therefore, it can be said that fuzzy clustering produces a better-balanced portfolio compared to traditional matrix-form clustering and the null hypothesis H40 is rejected.
It is interesting to observe the optimal weights that are allocated to each cluster under the two approaches while trying to compute the minimal balance error. Clusters 1, 2, 3 and 4 under crisp clustering are assigned weights of 0, suggesting that the optimal crisp portfolio should not consist of any customers from these clusters. In contrast, the optimal fuzzy portfolio comprised customers belonging to all the eight clusters with varying weights.
Implications for marketers
The main objective of portfolio analysis is to come up with a well-balanced collection of assets.33 Here, the assets are the customers of the organization. In contrast to sharp or crisp portfolio analysis, fuzzy portfolio analysis enables us to calculate a more theoretically efficient customer portfolio.33 The optimal weights that are found provide a guideline for the resource allocation decision for the firm.
The level of investment a business makes can be undertaken in proportion to the calculated optimal weights. For example, according to the crisp clustering technique, cluster 5 receives a weight of 0.51, suggesting that the customer portfolio should consist of 51 per cent of cluster 5 customers. According to the fuzzy clustering approach, cluster 5 customers should only comprise 17 per cent of the customer portfolio. Let us assume the organization sets the recommended investment level for a cluster 5 customer at £100 per customer. As per the traditional clustering approach, the level of investment towards cluster 5 customers should be 0.51 × 3076 customers × £100=£156 876. However, as per the fuzzy clustering approach, the level of investment towards cluster 5 customers should be 0.17 × 3076 customers × £100=£52 292. Thus, one can see that the traditional and fuzzy clustering approaches can result in very different resource allocation decisions for the firm.
Different recommended investment levels by the two approaches do not suggest anything about which approach is better. In order to determine which clustering approach results in a better-balanced portfolio, it is necessary to look at the corresponding balance errors that are obtained. It can be seen that fuzzy clustering results in a much smaller balance error than crisp clustering. Thus, marketers can adopt the fuzzy clustering approach to come closer to their objective of obtaining the most well-balanced portfolio and utilize the optimal weights that are produced to guide their resource allocation decisions.
CONCLUSION
In this research, the data are not found to be normally distributed. It is observed that the data follow a peak distribution and exhibit skewness to the right. The non-normal distribution of the data is a clustering prerequisite and is met satisfactorily. The clusters are found to be identifiable and distinguishable from each other in terms of the variables ‘Value’, ‘Cost’ and ‘ATUQ’. In other words, crisp cluster 1 is different from the other crisp clusters; crisp cluster 2 is different from the other crisp clusters and so on. This is found to be true for the fuzzy clusters too. Each cluster is found to have unique characteristics in terms of the value that it contributes, the cost incurred to retain the customers of the cluster and the number of unique products bought by the customers of the cluster. The size of the fuzzy clusters is found to be larger than that of the crisp clusters with the different alpha-cuts of 0.15, 0.2 and 0.3. These alpha-cuts are set according to the rule of the alpha-cuts being greater than or equal to 1/number of clusters. The real number of customers based on the total belongingness to each cluster is also presented. The fuzzy clusters are also seen to be contributing more value than that of the crisp clusters for the chosen alpha-cut values. Thus, it is established that fuzzy clustering results in more substantial clusters than crisp clustering for the chosen alpha-cuts. In addition, fuzzy clustering enables marketers to comment on the stability of the cluster by looking at the difference between the integer (found by setting alpha-cuts) and the real number of customers. It is also acknowledged that setting very high alpha-cuts can result in less substantial clusters and that the use of alpha-cuts allows marketers to become more aware of the substantiality of the fuzzy clusters under different circumstances. Fuzzy clustering results in the creation of a better-balanced portfolio than crisp clustering. The minimal balance error for fuzzy clustering is much closer to 0 than for sharp clustering. Corresponding optimal weights to be assigned to each cluster are also obtained. These weights act as benchmarks for resource allocation decisions.
LIMITATIONS
The challenge was to come up with parameters that allow comparison between the crisp and fuzzy clusters. Previous studies did not draw direct comparison between crisp and fuzzy clusters in the realm of customer portfolio analysis. Hence, there did not exist any parameters that were common to both crisp and fuzzy clusters, and thereby could be used as the bases of comparison. A limitation of the study is that it uses only two bases of comparison – substantiality and balance of portfolio. Further research must aim to discover more common bases of comparison between sharp and fuzzy clusters in order to provide a more comprehensive conclusion on their usability for marketers. Another base of comparison that future researchers could look at is homogeneity. It might be possible to calculate Intra-class Inertia – a measure of compactness – and Xie–Beni Index, a measure of compactness and separation for both crisp and fuzzy clusters. However, this may not be sufficient to say that one approach is more useful than the other till it is shown that the more homogeneous clusters have a significant impact on the marketer.
Once more parameters for comparison are found, a weighted average of these could be used to calculate a composite measure such as a ‘Cluster Attractiveness Score’ that may provide a more comprehensive measure of the usefulness of the clustering techniques. In addition, this composite measure may also act as a scoring tool within fuzzy and crisp clusters.
It should be noted that this research is exploratory in nature. Illustrations and examples have been used to discuss the managerial implications of the more substantial clusters and a better-balanced customer portfolio. Additional empirical research is needed to strengthen the claim of fuzzy clustering producing more useful results for organizations than crisp clustering. This research could be conducted using a larger sample and across a variety of industries.
References
Gok, O. (2009) Linking account portfolio management to customer information: Using customer satisfaction metrics for portfolio analysis. Industrial Marketing Management 38 (4): 433–439.
Kundisch, D., Sackmann, S. and Ruch, M. (2009) Transferring portfolio selection theory to customer portfolio management – The case of an e-tailer. In: D. Veit, D. Kundisch, T. Weitzel, F. Rabhi, F. Rajola and C. Weinhardt (eds.) Proceedings of the 3rd International Workshop on Enterprise Applications and Services in the Finance Industry. Springer Lecture Notes in Business Information Processing, Heidelberg: Springer, pp. 32–49.
Chalmeta, R. (2006) Methodology for customer relationship management. The Journal of Systems and Software 79 (7): 1015–1024.
Ittner, C. and Larcker, D. (1998) Are non financial measures leading indicators of financial performance? An analysis of customer satisfaction. Journal of Accounting Research 36 (Supplement): 1–35.
Ryals, L. (2003) Making customers pay: Measuring and managing customer risk and returns. Journal of Strategic Marketing 11 (3): 165–175.
Terho, H. and Halinen, A. (2007) Customer portfolio analysis practices in different exchange contexts. Journal of Business Research 60 (7): 720–730.
Rajagopal, R. and Sanchez, R. (2005) Analysis of customer portfolio and relationship management models: Bridging managerial dimensions. Journal of Business & Industrial Marketing 20 (6): 307–316.
Talwar, V., Burton, J. and Murphy, J. (2008) A non-matrix approach to customer relationship portfolio management: A case study from the UK industrial market context. Journal of Customer Behaviour 7 (3): 231–255.
Fiocca, R. (1982) Account portfolio analysis for strategy development. Industrial Marketing Management 11 (February): 53–62.
Turnbull, P.W. and Topcu, S. (1994) Customer profitability in relationship life cycles. In: W.G. Biemans and P.N. Ghauri (eds.) IMP Conference (10th): Meeting the Challenges of New Frontiers. Groningen, The Netherlands: University of Groningen.
Yorke, D.A. and Droussiotis, G. (1994) The use of customer portfolio theory: An empirical study. Journal of Business & Industrial Marketing 9 (3): 6–18.
Cunningham, M.T. and Homse, E. (1982) An interaction approach to marketing strategy. In: H. Håkansson (ed.) International Marketing and Purchasing of Industrial Goods: An Interaction Approach. Chichester, UK: Wiley, pp. 328–345.
Eng, T.-Y. (1999) An empirical investigation into strategic management theories with reference to a portfolio of customer relationships in the services sector. Phd Dissertation, UMIST, Manchester.
Campbell, N.C.G. and Cunningham, M.T. (1983) Customer analysis for strategy development in industrial markets. Strategic Management Journal 4 (4): 369–380.
Turnbull, P.W. and Zolkiewski, J. (1997) Profitability in customer portfolio planning. In: D. Ford (ed.) Understanding Business Markets: Interactions, Relationships and Networks, 2nd edn. London: The Dryden Press.
Shapiro, B.P., Rangan, V.K., Moriarty, R.T. and Ross, E.B. (1987) Manage customers for profits (not just sales). Harvard Business Review, September/October: 101–108.
Gelderman, C.J. (2003) A Portfolio Approach to the Development of Differentiated Purchasing Strategies. Doctoral Dissertation. Eindhoven University of Technology, Eindhoven, The Netherlands.
Torkul, O., Cedimoglu, I.H. and Geyik, A. (2006) An application of fuzzy clustering to manufacturing cell design. Journal of Intelligent & Fuzzy Systems 17 (2): 173–181.
Vercher, E., Bermudez, J. and Segura, J. (2006) Fuzzy portfolio optimization under downside risk measures. Fuzzy Sets and Systems 158 (7): 769–782.
Wang, J. and Hwang, W.L. (2005) A fuzzy set approach for R&D portfolio selection using a real options valuation model. Omega 35 (3): 247–257.
Dunn, J.C. (1974) Well-separated clusters and the optimal fuzzy partitions. Journal of Cybernetics 4 (1): 95–104.
Bezdek, J.C. (1981) Pattern Recognition with Fuzzy Objective Function Algorithms. New York: Plemun Press.
Hoppner, F. (1999) Fuzzy Cluster Analysis: Methods for Classification, Data Analysis, and Image Recognition. Chichester, UK: John Wiley.
Yang, M. (1993) A survey of fuzzy clustering mathematical computer modelling. Mathematical and Computer Modelling 18 (11): 1–16.
Watada, J. (1997) Fuzzy portfolio selection and its applications to decision-making. Tatra Mountains Mathematical Publications 13 (4): 219–248.
Tanaka, H. and Guo, P. (1999) Portfolio selection based on upper and lower exponential possibility distributions. European Journal of Operational Research 114 (1): 115–126.
Lin, C., Tan, B. and Hsieh, P.-J. (2005) Application of the fuzzy weighted average in strategic portfolio management. Decision Sciences 36 (3): 489–511.
Buyukozkan, G.L., Feyzioglu, O. and Nebol, E. (2008) Selection of the strategic alliance partner in logistics value chain. International Journal of Production Economics 113 (1): 148–158.
Chiu, C.M. and Hsu, M.-H. (2004) Predicting electronic service continuance with a decomposed theory of planned behaviour. Behaviour & Information Technology 23 (5): 359–373.
Bozdag, C. (2003) Fuzzy group decision making for selection among computer integrated manufacturing systems. Computers in Industry 51 (1): 13–29.
Danneels, E. and Kleinschmidtb, E.J. (2001) Product innovativeness from the firm's perspective: Its dimensions and their relation with project selection and performance. Journal of Product Innovation Management 18 (6): 357–373.
Thieme, R.J. and Song, M. (2000) Artificial neural network decision support systems for new product development project selection. Journal of Marketing Research 37 (4): 499–507.
Zumstein, D. (2007) Customer performance measurement: Analysis of the benefit of a fuzzy classification approach in customer relationship management. Diss. Vervielfältigte Masterarbeit University, Freiburg Schweiz.
Hunt, S.D. (1997) Competing through relationships: Grounding relationship marketing in resource-advantage theory. Journal of Marketing Management 13 (5): 431–445.
Cheng, C. and Chen, Y. (2008) Classifying the segmentation of customer value via RFM model and RS theory. Expert Systems With Applications 36 (3): 4176–7184.
Milley, A.H., Seabolt, J.D. and Williams, J.S. (1998) Data mining and the case for sampling. White paper, SAS Institute, Carey.
Hiziroglu, A. (2009) A Soft Computing Approach to Customer Segmentation. Manchester, UK: University of Manchester.
Changchien, S.W. and Lu, T.Z. (2001) Mining association rules procedure to support on-line recommendation by customers and products fragmentation. Expert Systems With Applications 20 (4): 325–335.
Author information
Authors and Affiliations
Corresponding author
Additional information
1works as an Assistant Professor at the Sakarya University Industrial Engineering Department. He has been covering courses related to Information Systems, Artificial Intelligence and Engineering Economy. His main research interest is the applications of soft computing technologies in customer analytics. Dr Hiziroglu has presented his research in leading conferences in the United Kingdom, United States, Germany, Greece, Cyprus, Denmark and Turkey. He has published articles in the Journal of Economic Studies, Journal of Intelligent and Fuzzy Systems and Journal of Research in Learning Technology. He is currently working as Director of European Framework Programmes at Sakarya University.
2works as Director of Marketing in Lypsa Diamonds Ltd, Mumbai. He has a Bachelor's degree in Management and a Master's in International Management from the London School of Economics (LSE). His Master's thesis was a comparative study between crisp and fuzzy clustering to conduct customer portfolio analysis in the supermarket industry.
3works within the Department of Management at (LSE) and is Marketing Fellow heading the International Marketing and Marketing Strategy courses. With a research interest in marketing resource allocation and ethical consumer decision making. Dr Talwar has presented his research in leading conferences in the United States, United Kingdom, India, Italy, Finland, Canada and Germany and has published in journals such as the Journal of Business Ethics and Journal of Customer Behaviour. His research paper on ‘Strategic Choice’ received best paper proceedings at the Academy of Management Conference in 2010.
Appendices
APPENDIX A
APPENDIX B
Operationalization of RFM values
We employ the weighted RFM method, and the weights for the RFM values are determined intuitively; for this study, they are 0.5, 0.25 and 0.5, respectively. In addition, we have followed a normalization process to prepare the data for the clustering algorithm. We need to normalize the values to the range of 0–1 using the following formula for all variables, except the Recency value.38

where Re sv is the normalized value of an attribute; Max xv and Min xv are the maximum and minimum values of the attribute, respectively; and E xv is the existing value of the attribute.
For the Recency value, we use the formula:38

The Recency value receives the above-mentioned unique treatment while normalization owing to its negative correlation with customer value unlike the other variables.
The variable ‘cost’ refers to the cost of retention and is estimated as being 1.75 per cent of the monetary value. This estimate is based on an informal opinion gathered from around 20 marketing experts.
APPENDIX C
Rights and permissions
About this article
Cite this article
Hiziroglu, A., Patwa, J. & Talwar, V. Customer portfolio analysis: Crisp classification versus fuzzy classification – Based on the supermarket industry. J Target Meas Anal Mark 20, 67–83 (2012). https://doi.org/10.1057/jt.2012.5
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1057/jt.2012.5